
کتاب Spark in Action
نوع محتوای کتاب
مبتنی بر پروژه
هدف یادگیری
حل مسئله عملی
نوع مسیر
صفر تا صد آماده برای کار
بر اساس تکنولوژی
علوم داده
بر اساس سطح علمی
متوسط
info نکات مهم قبل از خرید:
- نسخه کتاب فعلی به زبان لاتین میباشد.
- کتاب به صورت محصول میباشد و پس از خرید بلافاصله در دسترس شما قرار میگیرد.
- قبل از خرید، قسمت توضیحات تکمیلی مربوط به هر کتاب را مطالعه کنید.
- در صورت هرگونه سؤال با ایمیل و یا شماره پشتیبانی سایت در تماس باشید.
- درگاه پرداخت رمزارز نیز برای هموطنان خارج از کشور فعال است.
درباره این کتاب
کتاب Spark in Action با محوریت ابزار Apache Spark نسخه 3 جهت آشنایی و کار با آن منتشر شده است. این کتاب حدود 600 صفحهای به طور کامل کار با این ابزار متن باز را آموزش داده و همچنین دارای مثالهای عملی با زبانهای برنامهنویسی Python, Java و Scala میباشد. مطالعهی کتاب Spark in Action برای افراد تارهکار و همچنین حرفهای برای کار با ابزار Spark بسیار توصیه میشود. گذری…

کتابهای پیشنهادی این تخصص:
کتابهای پیشنهادی این تخصص:
نظرات کاربران
تجربیات خود را از خواندن این کتاب با دیگران به اشتراک بگذارید.
ثبت نظر جدید
هنوز دیدگاهی ثبت نشده است.
کتاب Spark in Action با محوریت ابزار Apache Spark نسخه 3 جهت آشنایی و کار با آن منتشر شده است. این کتاب حدود 600 صفحهای به طور کامل کار با این ابزار متن باز را آموزش داده و همچنین دارای مثالهای عملی با زبانهای برنامهنویسی Python, Java و Scala میباشد. مطالعهی کتاب Spark in Action برای افراد تارهکار و همچنین حرفهای برای کار با ابزار Spark بسیار توصیه میشود.
گذری کوتاه بر Apache Spark:
آپاچی اسپارک (Apache Spark) یک چارچوب رایانش توزیعشده متنباز است. این نرمافزار در ابتدا توسط دانشگاه کالیفرنیا، برکلی توسعه داده میشد که بعدها کد آن به بنیاد نرمافزار آپاچی هدیه گردید که از آن زمان توسط آنها نگهداری میشود. اسپارک یک رابط برنامهنویسی کاربردی برای برنامهنویسی تمام خوشهها با موازیسازی دادههای ضمنی و تحمل خطا فراهم میکند.
اسپارک از حافظه اصلی برای نگهداری دادههای برنامه استفاده میکند که این امر باعث سریعتر اجرا شدن برنامهها میشود (برخلاف مدل نگاشت/کاهش که از دیسک به عنوان مکان ذخیرهسازی دادههای میانی استفاده میکند). همچنین یکی دیگر از مواردی که باعث افزایش کارایی اسپارک میشود، استفاده از مکانیسم حافظه نهان هنگام استفاده از دادههایی است که قرار است دوباره در برنامه استفاده شوند. اینکار باعث کاهش سربار ناشی از خواندن و نوشتن از دیسک میشود.
یک الگوریتم برای پیادهسازی در مدل نگاشت/کاهش، ممکن است به چندین برنامه مجزا تقسیم شود و در هنگام اجرا هر بار باید دادهها از دیسک خوانده شده، پردازش شوند و دوباره در دیسک نوشته شوند. اما با استفاده از مکانیسم حافظه نهان در اسپارک، دادهها یکبار از دیسک خوانده میشوند و در حافظه اصلی کَش میشوند و عملیاتهای متفاوت بروی آن اجرا میشود. در نتیجه استفاده از این روش نیز باعث کاهش چشمگیر سربار ناشی از ارتباط با دیسک در برنامهها و بهبود کارایی میشود.
مروری بر کتاب Spark in Action نسخه 2:
کتاب Spark in Action به 4 قسمت و 18 پیوست تقسیم شده است.
قسمت 1 – نظریهای که توسط نمونههای بسیار جذاب منتقل شده است
بخش اول کتاب Spark in Action، به شما نکات کلیدی Apache Spark را آموزش میدهد. در این قسمت تئوری و مفاهیم کلی را همراه با مثالها و نمودارهای متعدد یاد خواهید گرفت. این قسمت به سادگی یک کتاب طنز (Comic) برای مخاطب توضیح داده شده است.
■ فصل 1 – Spark چیست؟
فصل اول کتاب Spark in Action، مقدمهای کلی با یک مثال ساده است. در این دلیل این را خواهید آموخت که چرا Apache Spark یک سیستم عامل تحلیلی توزیع شده است.
■ فصل 2 – معماری و جریان
در این فصل شما با یک روند ساده Apache Spark آشنا خواهید شد.
■ فصل 3 – نقش باشکوه چارچوب داده
در این فصل در مورد کارایی قاب داده (DataFrame) توضیحاتی داده خواهد شد، همچنین در مورد ترکیب API و قابلیت ذخیرهسازی Apache Spark مطالبی را فرا خواهید آموخت.
■ فصل 4 – Spark برای تنبلها!
در این فصل، Apache Spark و RDBMS را با یکدیگر مقایسه میشوند و نمودار چرخشی مستقیم (DAG) معرفی خواهد شد.
■ فصل 5 – ساخت یک برنامک ساده برای استقرار
■ فصل 6 – استقرار یک برنامه ساده
■ فصل 5 و 6 به هم پیوند دارند: شما یک برنامه کوچک ایجاد خواهید کرد، یک خوشه میسازید و برنامه خود را مستقر کنید. فصل 5 در مورد ساخت یک برنامه کوچک است در صورتی که فصل 6 طریقه استفاده از برنامه را آموزش خواهد داد.
بخش 2 – جذب
در بخش دوم کتاب Spark in Action، شما شروع به تمرکز بر روی مثالهای عملی در محیط واقعی خواهید کرد. جذب (Ingestion) فرآیند آوردن دادهها به Apache Spark است. این فرآیند پیچیده نیست، و با استفاده از امکانات ابزار Apache Spark این کار انجام خواهد شد.
در تصویر زیر، مفهوم Ingestion در Apache Spark را مشاهده میکنید.
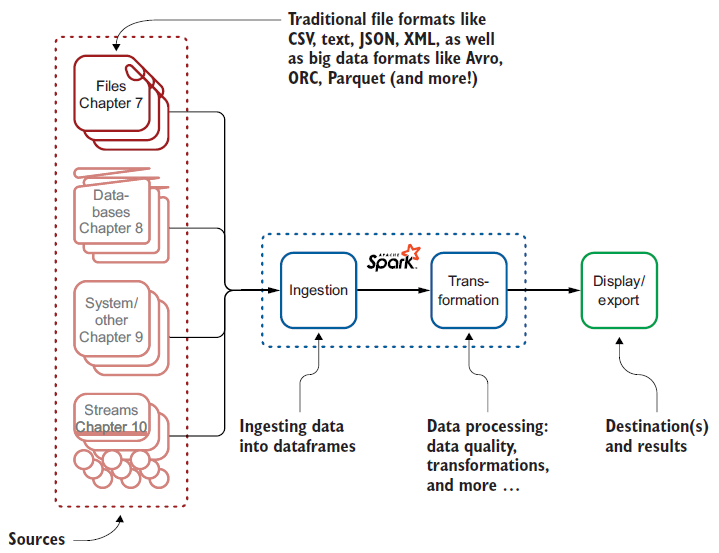
■ فصل 7 – انتقال از پروندهها
انتقال دادهها را از پروندهها را شرح میدهد: CSV ،text ،JSON ،XML ،Avro ،ORC، و Parquet. هر قالب پرونده مثال خاص خود را دارد.
■ فصل 8 – انتقال از پایگاهدادهها
شامل انتقال از پایگاههای داده است: دادهها هم از پایگاهدادههای رابطهای و هم مخزن دادهها میتوانند منتقل شوند.
■ فصل 9 – انتقال حرفهای: پیدا کردن منابع داده و ساخت یک منبع داده شخصی
این فصل، مربوط به انتقال هر موردی از منابع دادههای سفارشی به Apache Spark است.
■ فصل 10 – انتقال داده از طریق جریان سازهای (Structured Streaming)
روی دادههای جریانی متمرکز است.
قسمت 3 – تبدیل دادههای خود
قسمت سوم کتاب Spark in Action، در مورد تبدیل دادهها است: این قسمت را نویسنده کتاب Spark in Action به عنوان “بلند کردن دادههای سنگین” نامگذاری کرده است. در این قسمت شما در مورد کیفیت داده، تحول و انتشار دادههای پردازش شده خود، مطالبی را خواهید آموخت. این قسمت بزرگترین بخش این کتاب است که در مورد استفاده از DataFrame با SQL و با API آن صحبت میکند، علاوه بر آن، تراکم، ذخیرهسازی موقت داده و گسترش Spark به وسیله UDF مطالبی را خواهید آموخت.
■ فصل 11 – کار با SQL
در مورد زبان جستجوی معروف SQL است.
■ فصل 12 – تبدیل دادههای شما
نحوه انجام تبدیل داده را به شما میآموزد.
■ فصل 13 – تبدیل کردن کل اسناد
تبدیل دادهها را به سطح کل اسناد گسترش میدهد. این فصل همچنین توابع ایستا را توضیح میدهد، که یکی از بسیاری از جنبههای مهم Apache Spark است.
■ فصل 14 – گسترش تبدیلها با توابع تعریف شده توسط کاربر
این فصل، درباره گسترش Apache Spark با استفاده از توابع تعریف شده توسط کاربر است.
■ فصل 15 – تجیمع دادههای خود
■ تراکم ( Aggregations) که یکی از مفاهیم پایگاه داده شناخته شده است، ممکن است کلید تجزیه و تحلیل باشد. فصل 15 جمعبندیها را شامل میشود، هم آنهایی که در Spark و هم جمعهای سفارشی موجود است.
قسمت 4 – پیشی گرفتن
سرانجام، قسمت 4 در مورد نزدیک شدن به تولید و تمرکز بر پیشرفتهتر است.
در این فصل درباره موضوعاتی همچون پارتیشنبندی و خروجی گرفتن (Export) از دادهها، محدودیتهای استقرار (از جمله به ابر) و بهینهسازی اطلاعاتی کسب خواهید کرد.
■ فصل 16 – حافظه ذخیرهسازی موقت و Checkpoint: بهبود کارایی Spark
روی تکنیکهای بهینهسازی از جمله، ذخیرهسازی موقت داده (Caching) و تکنیک Checkpointing تمرکز دارد.
■ فصل 17 – خروجی داده و ساخت خطوط لوله (Data Pipelines) کامل
درباره خروجی گرفتن دادهها به پایگاهها و پروندهها است. این فصل نیز نحوه استفاده از Delta Lake، پایگاه دادهای که در کنار هسته Spark’s قرار دارد را توضیح میدهد.
■ فصل 18 – بررسی محدودیتهای استقرار: درک اکوسیستم
جزئیات معماری و امنیت مورد نیاز برای استقرار را ذکر میکند. قطعاً این فصل، مطالب عملی کمتری را دارا میباشد، اما شامل اطلاعات مهمی است.
ضمائم کتاب Spark in Action، اگرچه ضروری نیستند، اما اطلاعات زیادی را به همراه دارند: نصب، عیبیابی و زمینهسازی. بسیاری از آنها منابع خوبی برای استفاده از Apache Spark در زبان برنامهنویسی جاوا هستند.
به طور مثال در تصویر زیر، نصب Apache Spark در قسمت ضمائم کتاب به طور کامل توضیح داده شده است.

در تصویر زیر، شمایلنگاری (Icongraphy) کتاب Spark in Action را مشاهده میکنید.
همچنین شما میتوانید برای مطالعهی ابزار Hadoop جهت دادهکاوی از کتاب Hadoop The Definitive Guide نیز استفاده کنید.
سرفصلهای کتاب Spark in Action:
- THE THEORY CRIPPLED BY AWESOME EXAMPLES
- Architecture and flow
- The majestic role of the dataframe
- Fundamentally lazy
- Building a simple app for deployment
- Deploying your simple app
- INGESTION
- Ingestion from files
- Ingestion from databases
- Advanced ingestion: finding data sources and building you
- Ingestion through structured streaming
- TRANSFORMING YOUR DATA
- Working with SQL
- Transforming your data
- Transforming entire documents
- Extending transformations with user-defined functions
- Aggregating your data
- GOING FURTHER
- Cache and checkpoint: Enhancing Spark’s performances
- Exporting data and building full data pipelines
- Exploring deployment constraints: Understanding the ecosystem
- Appendix
- Index
فایل کتاب Spark in Action را میتوانید پس از پرداخت دریافت کنید.