

کتاب DATA MINING Concepts, Models, Methods, and Algorithms یا به معنای مختصر داه کاوی، مفاهیم، مدلها، متدها و الگوریتمها، از جدیدترین کتابهای داده کاوی و شرح الگوریتمها و مفاهیم آن است. کتاب داده کاوی در سال 2020 به چاپ رسیده و حدود 670 صفحه دارد. این کتاب شامل 14 فصل مختلف از اصول، روشها و الگوریتمهای جدید و مرسوم داده کاوی میباشد. خواندن کتاب داده کاوی برای افراد علاقهمند و یا پژوهشگر در زمینه داده کاوی بسیار توصیه میشود.
برای مطالعه تخصصی درباره تحلیل داده به وسیله زبان پایتون با مثالهای عملی و کاربردی میتوانید از کتاب Hands-on Exploratory Data Analysis with Python استفاده کنید.
آنچه در کتاب داده کاوی خواهید آموخت:
فصل 1: مفاهیم داده کاوی
- درک نیاز به تجزیه و تحلیل مجموعه دادههای بزرگ، پیچیده و غنی از اطلاعات.
- مشخص کردن اهداف و وظایف اصلی فرآیند داده کاوی.
- توصیف پایههای فناوری داده کاوی.
- مشخص کردن برخی از روندهای تکراری فرآیند داده کاوی و مراحل اساسی آن.
- توضیح تأثیر کیفیت داده بر روند داده کاوی.
- برقراری ارتباط بین انبار کردن داده و داده کاوی.
- بحث در رابطه با مفاهیم کلان داده و علم داده.
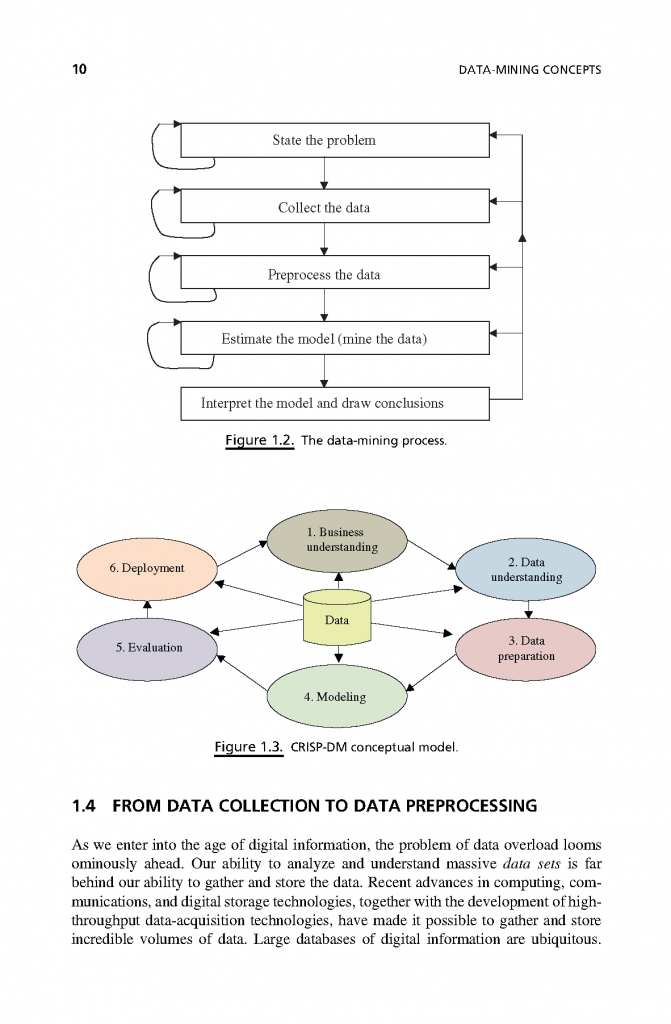
فصل 2: آمادهسازی داده
- تجزیه و تحلیل نمایشها و ویژگیهای اساسی مجموعه دادههای خام و بزرگ.
- اعمال روشهای مختلف نرمالسازی بر روی خصوصیات عددی.
- تشخیص تکنیکهای مختلف برای تهیه دادهها، از جمله ویژگی دگرگونی.
- مقایسه روشهای مختلف برای حذف مقادیر از دست رفته.
- ساختن روشی برای نمایش یکنواخت دادههای وابسته به زمان.
- مقایسه تکنیکهای مختلف برای تشخیص دور.
- پیادهسازی برخی از تکنیکهای پیشپردازش دادهها.
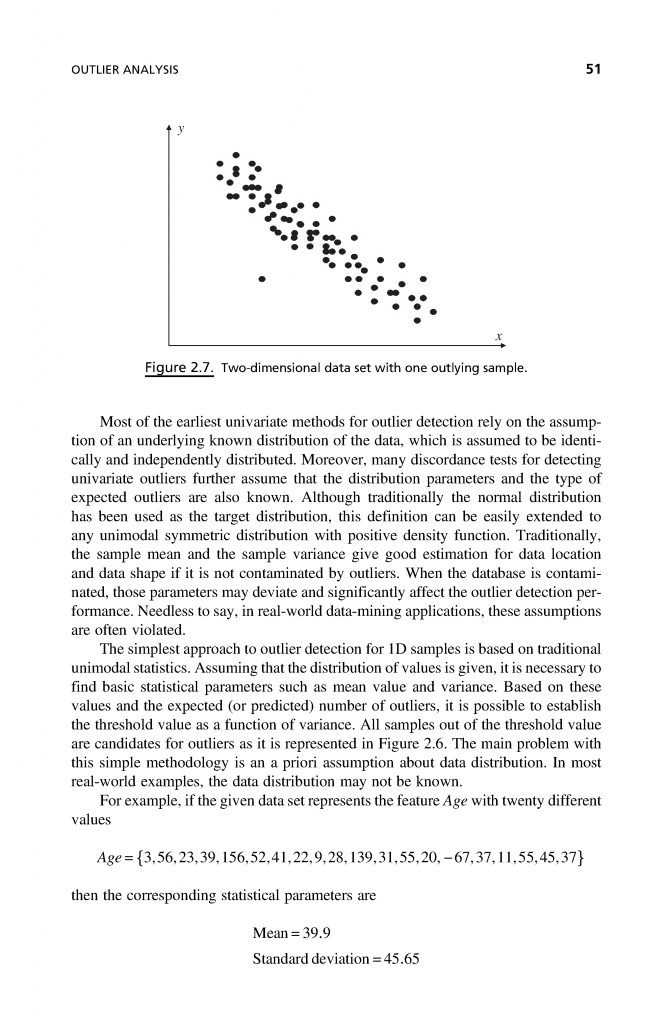
فصل 3: کاهش حجم دادهها
- شناسایی تفاوتها را در کاهش ابعاد بر اساس ویژگیها، موارد و کاهش تکنیکهای ارزش.
- توضیح مزایای کاهش دادهها در مرحله پیشپردازش فرآیند دادهپردازی.
- درک اصول اساسی انتخاب و ترکیب ویژگی وظایف با استفاده از روشهای آماری مربوطه.
- استفاده و مقایسه روش مبتنی بر آنتروپی و تجزیه و تحلیل مؤلفههای اصلی برای رتبهبندی ویژگیها.
- شناخت اصول اساسی روشهای ChiMerge و BinBased برای کاهش مقادیر گسسته و پیادهسازی آن.
- رویکردها را در مواردی که کاهش مبتنی بر افزایشی و نمونههای متوسط.
فصل 4: درک مفاهیم از دادهها
- تجزیه و تحلیل مدل کلی یادگیری استقرایی در محیطهای متغیر.
- توضیح درباره اینکه چگونه ماشین یادگیری یک تابع تقریب را از مجموعهای از توابع انتخاب میکند؟
- معرفی مفاهیم عملکردی ریسک برای رگرسیون و طبقهبندی چالشها و مسائل.
- شناسایی مفاهیم اساسی در تئوری یادگیری آماری (SLT) و بحث در مورد تفاوت بین اصول استقرایی، به حداقل رساندن خطر تجربی (ERM) و به حداقل رساندن ریسک ساختاری (SRM).
- بحث در مورد جنبههای عملی مفهوم بُعد Vapnik – Chervonenkis (VC) به عنوان یک ساختار مطلوب برای کارهای یادگیری استقرایی.
- مقایسه کارهای مختلف یادگیری استقرایی با استفاده از تفسیر گرافیکی توابع تقریبی در یک فضای 2 بعدی.

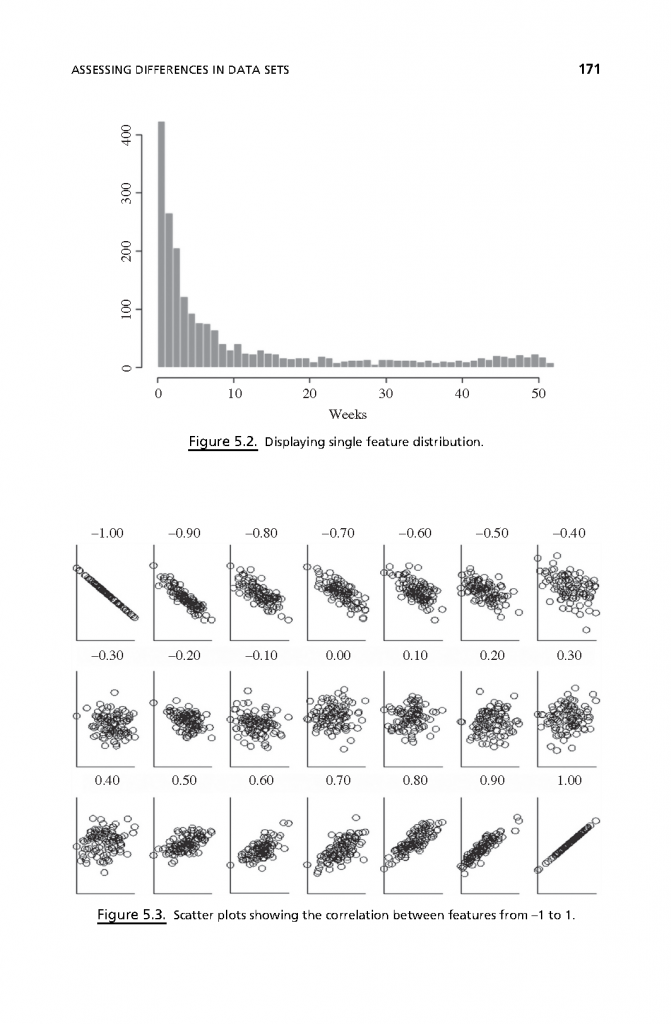
فصل 5: روشهای ایستا
- توضیح روشهای استنباط آماری که معمولاً در برنامههای کاربردی داده کاوی استفاده میشوند.
- شناسایی پارامترهای آماری مختلف را برای ارزیابی تفاوت در مجموعه دادهها.
- توصیف مؤلفهها و اصول اساسی دستهبندی بیز ساده و روش رگرسیون لجستیک.
- معرفی مدلهای لگاریتم خطی با استفاده از تجزیه و تحلیل جداول توافقی.
- بحث درباره مفاهیم تجزیه و تحلیل ANOVA و تجزیه و تحلیل افتراقی خطی نمونههای چند بعدی.
فصل 6: درختان تصمیم و قانون
- تجزیه و تحلیل ویژگیهای یک روش مبتنی بر منطق برای طبقهبندی چالشها و مسائل.
- توصیف تفاوت بین نمایش درخت و تصمیم قانون در یک مدل طبقهبندی نهایی.
- تشریح الگوریتم C4.5 برای تولید درخت تصمیم و قوانین تصمیم را به طور عمیق.
- شناسایی تغییرات الگوریتم C4.5 هنگام وجود مقادیر از دست رفته در آموزش یا آزمایش مجموعه دادهها.
- معرفی مشخصات اساسی الگوریتم CART و شاخص جینی.
- چه زمان و چگونه از روشهای هرس برای کاهش پیچیدگی استفاده از درختان تصمیم و قوانین تصمیمگیری استفاده کنیم؟
- خلاصه کردن محدودیتهای ارائه مدل طبقهبندی به وسیله درختهای تصمیم و قوانین تصمیمگیری.

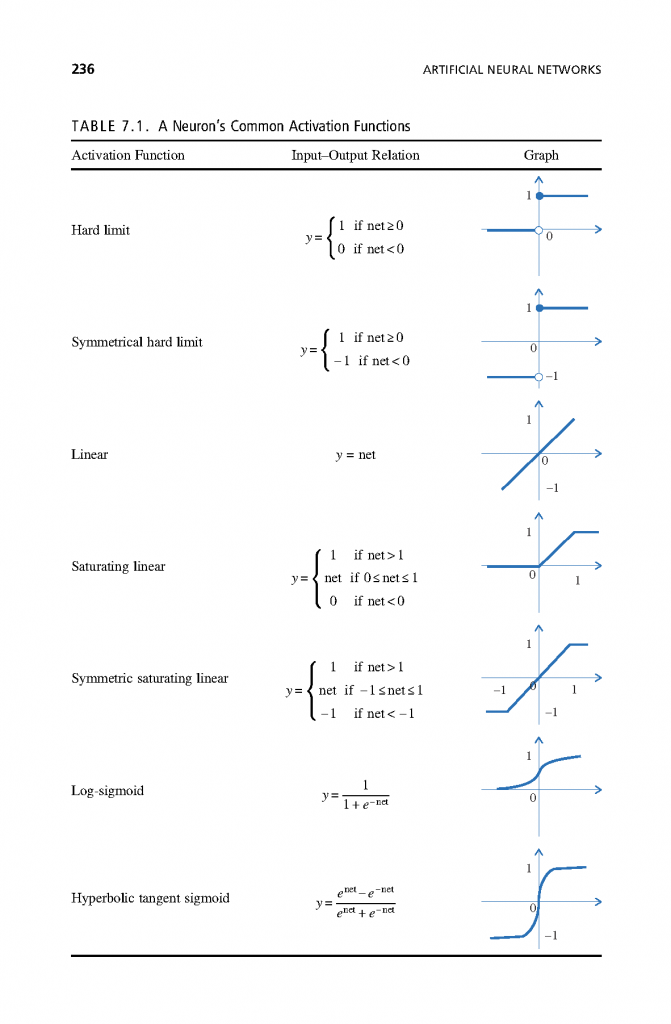
فصل 7: شبکههای عصبی مصنوعی
- شناسایی اجزای اساسی شبکههای عصبی مصنوعی و خصوصیات و تواناییها آنها.
- توصیف وظایف یادگیری متداول مانند ارتباط الگو، شناخت الگو، تقریب، کنترل و فیلتر کردن که توسط شبکههای عصبی مصنوعی انجام میشود.
- مقایسه معماری شبکه عصبی مصنوعی مختلف مانند feedforward و شبکههای مکرر و بحث در مورد برنامههای آنها.
- توضیح فرآیند یادگیری در سطح یک نورون مصنوعی و گسترش آن برای شبکههای عصبی پیشخوان چند نفره.
- مقایسه فرآیندها و وظایف یادگیری شبکههای رقابتی و شبکههای feedforward.
- ارائه اصول اساسی نقشههای کوهنن و کاربردهای آنها.
فصل 8: یادگیری کامل
- توضیح ویژگیهای اساسی روشهای یادگیری جمعی.
- تفاوت بین پیادهسازیهای مختلف طرحهای ترکیبی برای فراگیران مختلف
- مقایسه بین روشهای Bagging و Boosting.
- توضیح خصوصیات اصلی الگوریتم جنگل تصادفی.
- معرفی الگوریتم AdaBoost و مزایای آن.

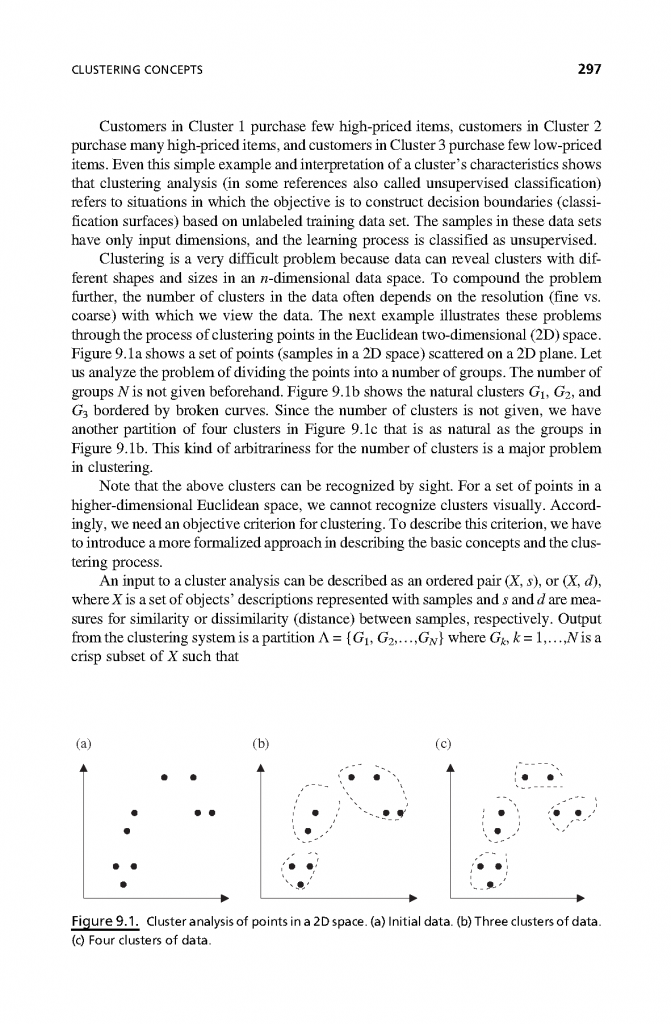
فصل 9: آنالیز خوشه
- تفاوت بین نمایشهای مختلف خوشهها و اندازهگیریهای مختلف شباهتها.
- مقایسه ویژگیهای اساسی الگوریتم خوشهبندی تجمعی و بخشی.
- پیادهسازی الگوریتمهای تجمعی با استفاده از اندازههای تشابه تک پیوندی یا پیوند کامل.
- پیادهساری روش K-means برای خوشهبندی بخشی و تجزیه و تحلیل پیچیدگی آن.
- توضیح الگوریتمهای خوشهای افزایشی و شرح مزایا و معایب آن.
- معرفی مفاهیم خوشهبندی چگالی و الگوریتمهای DBSCAN و BIRCH.
- بحث درباره دشواری اعتبار سنجی نتایج خوشهبندی.
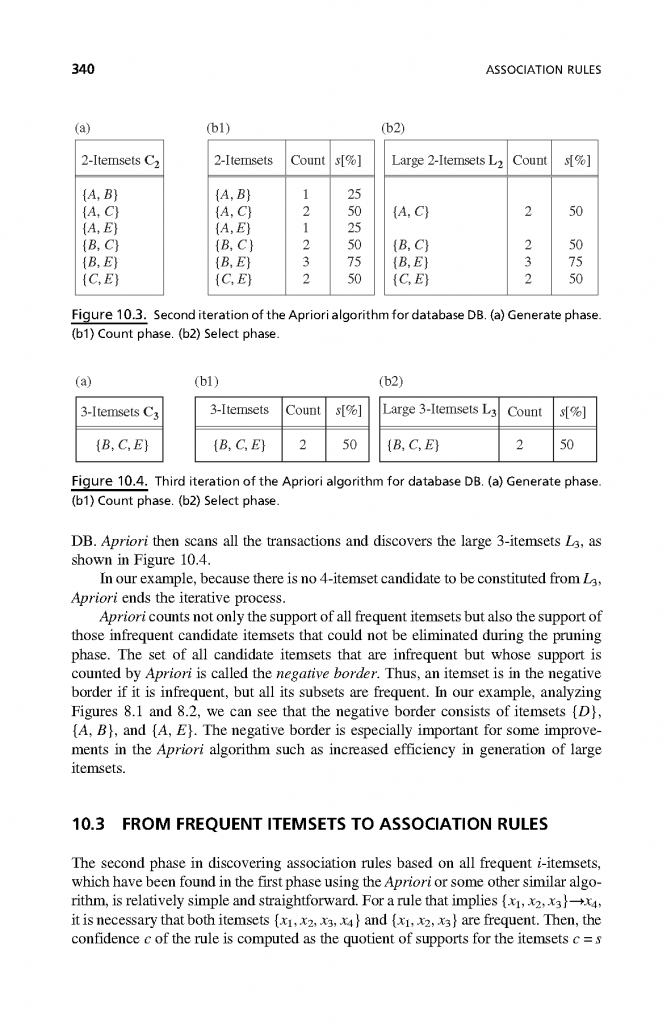
فصل 10: قوانین انجمنی
- توضیح شخصیت مدلسازی محلی تکنیکهای قاعده ارتباط.
- تجزیه و تحلیل ویژگیهای اساسی پایگاههای داده بزرگ معاملات.
- توضیح الگوریتم Apriori و تمام مراحل آن را از طریق مثالهای مصور.
- مقایسه روش رشد الگوی مکرر با الگوریتم Apriori.
- تشریح راه حل تولید قوانین ارتباط از مجموعههای مكرر.
- توضیح کشف ارتباطات چند بعدی.
- گسترش روش رشد FP برای مشکلات طبقهبندی را معرفی کنید.
فصل 11: وب کاوی و متن کاوی
- توضیح مشخصات وب کاوی.
- معرفی طبقهبندی وب کاوی و زیرمجموعههای آن.
- توصیف وب کاوی با استفاده از الگوریتمهای HITS ،LOGSOM و pathtraversal.
- توصیف رتبهبندی مستقل از پرس و جو در صفحات وب و ویژگیهای اصلی آن با استفاده از الگوریتم PageRank.
- استفاده از یک چارچوب متن کاوی را با مشخص کردن مراحل آن.
- طرح روش نمایهسازی معنایی نهفته.

فصل 12: مطالب پیشرفته در داده کاوی
- تجزیه و تحلیل ویژگیهای الگوریتمهای Graph-Mining با مثالهای مصور.
- شناسایی تغییرات مورد نیاز در الگوریتم داده کاوی زمانی که مؤلفههای موقت و مکانی معرفی میشوند.
- معرفی مشخصات اساسی الگوریتمهای داده کاوی توزیع شده و تغییرات خاص برای خوشهبندی توزیع شده DBSCAN.
- توصیف تفاوت بین علیت و همبستگی.
- معرفی اصول اولیه در مدلسازی شبکه بیزی.
- آشنایی با حریم خصوصی در فرآیند داده کاوی.
- خلاصه جنبههای اجتماعی و حقوقی برنامههای داده کاوی.
- رجستهسازی مفاهیم رایانش ابری، چارچوب Hadoop و نقشه / الگوی برنامهنویسی را کاهش دهید.
- توضیح اصول اساسی یادگیری تقویتکننده و فهم روش Q-learning.

فصل 13: الگوریتمهای ژنتیک
- شناسایی الگوریتمهای مؤثر برای راهحلهای تقریبی بهینهسازی مشکلات توصیف شده با مجموعه دادههای بزرگ.
- اصول و مفاهیم اساسی تکامل طبیعی و شبیهسازی شده را مقایسه کنید تکامل بیان شده از طریق الگوریتمهای ژنتیک.
- شرح مراحل اصلی الگوریتم ژنتیک با مثالهای گویا.
- توضیح عملگرهای ژنتیکی استاندارد و غیراستاندارد مانند مکانیزمی برای بهبود راهحلها
- بحث درباره مفهوم طرحواره با مقادیر غیرمهم و کاربرد آن برای بهینهسازی تقریبی.
- الگوریتم ژنتیک در مشکل فروشنده در حال سفر و اعمال بهینهسازی قوانین طبقهبندی به عنوان نمونههایی از بهینهسازیهای سخت.

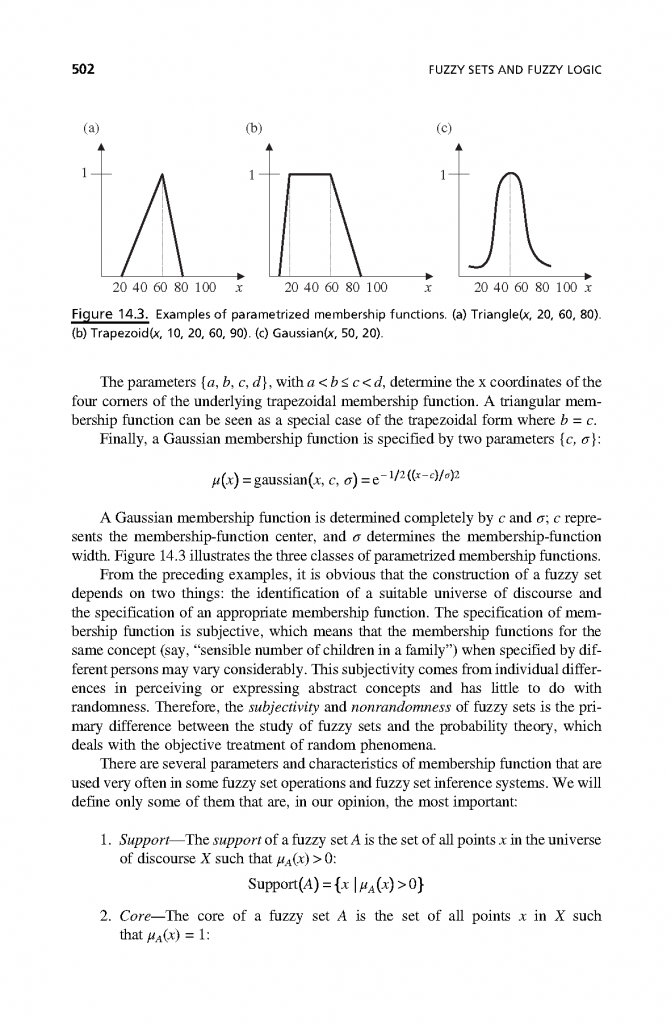
فصل 14: مجموعههای فازی و منطق فازی
- توضیح مفهوم مجموعههای فازی با تفسیر رسمی به صورت مداوم و حوزههای گسسته.
- تجزیه و تحلیل ویژگیهای مجموعههای فازی و عملیات مجموعههای فازی.
- اصل پسوند را به عنوان یک مکانیسم اساسی برای استنباطهای فازی توصیف کنید.
- در مورد اهمیت عدم دقت زبان و محاسبه با آنها در بحث کنید فرآیندهای تصمیمگیری.
- روشهای ارزیابی چند عاملی و استخراج یک مدل مبتنی بر قاعده فازی از مجموعه دادههای عددی بزرگ.
- درک اینکه چرا محاسبات فازی و سیستمهای فازی قسمت مهمی از آن هستند فناوری داده کاوی.
فصل 15: روشهای مصورسازی
- تشخیص اهمیت تجزیه و تحلیل درک بصری در انسان و کشف تکنیکهای مناسب تجسم داده.
- تفاوت بین تکنیک تجسم علمی و تجسم اطلاعات.
- درک ویژگیهای اساسی هندسی، آیکون محور، پیکسلگرا، و تکنیکهای سلسله مراتبی در تجسم مجموعههای بزرگ داده.
- توضیح روش مختصات موازی و تجسم شعاعی برای مجموعه دادههای n بعدی.
- تجزیه و تحلیل الزامات سیستمهای تجسم پیشرفته در داده کاوی.

سرفصلهای کتاب داده کاوی:
- Data-Mining Concepts
- Preparing the Data
- Data Reduction
- Learning from Data
- Statistical Methods
- Decision Trees and Decision Rules
- Artificial Neural Networks
- Ensemble Learning
- Cluster Analysis
- Association Rules
- Web Mining and Text Mining
- Advances in Data Mining
- Genetic Algorithms
- Fuzzy Sets and Fuzzy Logic
- Visualization Methods