

{kind=link}
{kind=link}
{kind=link}
{kind=link}
کتاب Building Serverless Applications on Knative: A Guide to Designing and Writing Serverless Cloud Applications (ساخت برنامه های بدون سرور در Knative: راهنمای طراحی و نوشتن برنامه های ابری بدون سرور) در 4 بخش مختلف به شرح فلسفهی برنامههای بدون سرور در محیط رایانش ابری خواهد پرداخت و با استفاده از ابزار Knative به صورت عملیاتی مفاهیم برنامهی بدون سرور را پیاده میکند.
در ادامه مقدمهای از کتاب Building Serverless Applications on Knative را از زبان نویسنده شرح خواهیم داد.
مقدمهای بر کتاب Building Serverless Applications on Knative:
بدون سرور به یکی از نقاط اصلی فروش ارائهدهندگان خدمات ابری تبدیل شده است. در چهار سال گذشته، صدها سرویس از ارائهدهندگان بزرگ ابر و ارائههای خدمات کوچکتر بهعنوان «بدون سرور» نامگذاری یا تغییر نام دادهاند.
واضح است که بدون سرور ارتباطی با خدمات ارائه شده از طریق شبکه دارد، اما بدون سرور چیست و چرا اهمیت دارد؟ چه تفاوتی با کانتینرها، عملکردها یا فناوریهای بومی ابری دارد؟ در حالی که اصطلاحات و تعاریف دائماً در حال تغییر هستند، این کتاب با هدف برجسته کردن ویژگیهای اساسی فناوریهای بدون سرور و توضیح اینکه چرا نام مستعار بدون سرور در حال افزایش محبوبیت است.
کتاب Building Serverless Applications on Knative در درجه اول بر روی سیستمهای محاسباتی بدون سرور تمرکز دارد. یعنی سیستمهایی که نرمافزار تعریفشده توسط کاربر را اجرا میکنند، به جای اجرای یک سیستم با عملکرد ثابت مانند ذخیرهسازی، نمایهسازی یا صف پیام. (سیستمهای ذخیرهسازی بدون سرور نیز وجود دارند، اما تمرکز اصلی این کتاب نیستند! ) با این گفته، مرز بین ذخیرهسازی با عملکرد ثابت و محاسبات همه منظوره هرگز آنقدر واضح و واضح نیست که تئوری میخواهد – برای مثال، سیستمهای پایگاه دادهای که از نحو پرس و جوی SQL پشتیبانی میکنند، ذخیرهسازی، نمایهسازی و اجرای برنامههای پرس و جوی اعلامی نوشته شده در SQL را ترکیب میکنند.
در حالی که معماری سیستمهای با عملکرد ثابت میتواند برای تنظیم عملکرد جذاب و مهم باشد، این کتاب در درجه اول بر محاسبات بدون سرور متمرکز است زیرا رابطی با بیشترین درجه آزادی برای نویسندگان برنامه و سیستمی است که آنها به احتمال زیاد روزانه با آن تعامل دارند.
اگر هنوز کاملاً مطمئن نیستید که بدون سرور چیست، نگران نباشید. با توجه به تعداد محصولات مختلف موجود در بازار، واضح است که اکثر مردم در یک قایق هستند. سیر تکامل اصطلاح «بدون سرور» را در «پسزمینه» مقدمه ترسیم میکنیم و سپس در فصل ۱ تعریف دقیقی ارائه میکنیم.
کتاب Building Serverless Applications on Knative برای چه افرادی است؟
مخاطبان اصلی این کتاب مهندسان نرم افزار۱ و فناورانی هستند که یا با بدون سرور آشنا نیستند یا به دنبال تعمیق درک خود از اصول و بهترین شیوههای مرتبط با معماری بدون سرور هستند.
پزشکان جدیدی که میخواهند فوراً وارد نوشتن برنامههای بدون سرور شوند، میتوانند از فصل ۲ شروع کنند، اگرچه من فصل ۱ کتاب Building Serverless Applications on Knative را برای توضیحات بیشتر در مورد اینکه چه اتفاقی میافتد و چرا بدون سرور اهمیت دارد، توصیه میکنم. فصل ۳ مطالب کاربردی بیشتری برای ایجاد درک عمیقتر از معماری پلتفرم Knative مورد استفاده در مثالها ارائه میکند.
ترتیب فصلها باید برای خوانندگانی که با بدون سرور آشنا هستند طبیعی باشد. فصلهای ۵ و ۶ چک لیستی از الگوهای استاندارد برای اعمال بدون سرور ارائه میدهند، در حالی که فصل ۸ کتاب Building Serverless Applications on Knative به بعد نوعی «کارت بینگو» از علائم هشدار دهنده بدون سرور و طرحهای راهحل ارائه میکند که ممکن است به صورت روزانه مفید باشد. زمینه تاریخی فصل ۱۱ همچنین نقشهای از جوامع فناوری قبلی را برای بررسی الگوها و راه حلها ارائه میدهد.
برای خوانندگانی که علاقه بیشتری به گرفتنایدههای بزرگ بدون سرور دارند، فصلهای ۱، ۴ و ۷ کتاب Building Serverless Applications on Knative دارای جواهرات جالبی هستند تا درک عمیقتر وایدههای جدید را القا کنند. زمینه تاریخی فصل ۱۱ و پیشبینیهای آینده نیز ممکن است برای درک قوس سیستمهای نرمافزاری که منجر به اجرای فعلی پیشنهادات بدون سرور بزرگتر شده است، جالب باشد.
برای خوانندگانی که نه تنها در زمینه محاسبات بدون سرور، بلکه در زمینه توسعه بومی باطن یا ابری نیز تازه کار هستند، باقیمانده این پیشگفتار، مطالبی پس زمینه برای کمک به تنظیم صحنه ارائه میدهد. مانند بسیاری از مهندسی نرمافزار، این حوزهها به سرعت حرکت میکنند، بنابراین تعاریفی که در اینجا ارائه میکنم ممکن است تا زمانی که این کتاب را میخوانید تا حدودی تغییر کرده باشد. در صورت شک، این کلمات کلیدی و توضیحات ممکن است در زمان جستجوی خدمات معادل در محیط انتخابی شما، زمان صرفهجویی کنند.
زمینه
در طول شش سال گذشته، اصطلاحات «بومی ابر»، «بدون سرور» و «ظروف» همگی در معرض دورهای پی درپی از تبلیغات و تعریف مجدد قرار گرفتهاند، تا جایی که حتی بسیاری از تمرینکنندگان در تلاش هستند تا تعاریف را رعایت کنند یا به طور کامل با آنها موافقت کنند.
از این اصطلاحات هدف بخشهای زیر ارائه تعاریف برخی از نکات مهم مرجع در بقیه کتاب است، اما بسیاری از این تعاریف احتمالاً به تکامل خود ادامه خواهند داد – آنها را به عنوان زمینه مرجع کلی برای بقیه کتاب Building Serverless Applications on Knative در نظر بگیرید، اما نه به عنوان یک انجیل واقعی. محاسبات بدون سرور با جوانه زدن و رشدایدهها، تعاریف تغییر میکنند و باغهای ابری بومی و بدون سرور در شش سال گذشته با رشد جدید شورش کردهاند.
همچنین توجه داشته باشید که این پسزمینه بهگونهای سازماندهی شده است که وقتی از ابتدا تا انتها خوانده میشود، منطقی به نظر میرسد، نه بهعنوان یک رکورد تاریخی از آنچه در ابتدا آمده است. بسیاری از این مناطق به طور مستقل از یکدیگر توسعه یافته و سپس پس از گلدهی اولیه خود (کاشت مجددایدهها از یک باغ به باغ دیگر در طول مسیر) به هم رسیدند و ترکیب شدند.
کانتینرها
کانتینرها – چه فرمت Docker یا Open Container Initiative (OCI) – مکانیزمی را برای تقسیم یک ماشین میزبان به چندین محیط زمان اجرا مستقل ارائه میدهند. برخلاف ماشینهای مجازی (VMs)، محیطهای کانتینری یک هسته سیستمعامل واحد را به اشتراک میگذارند که چند مزیت را ارائه میدهد:
سربار سیستم عامل کاهش یافت، زیرا فقط یک سیستم عامل در حال اجرا است
این کانتینرها را به اجرای همان سیستم عامل میزبان، معمولاً لینوکس، محدود میکند. (کانتینرهای ویندوز نیز وجود دارند اما بسیار کمتر مورد استفاده قرار میگیرند. )
بستههای نرمافزاری ساده شده که مستقل از درایورهای سیستم عامل و سختافزار اجرا میشوند
این بستهها برای اجرای توزیعهای مختلف لینوکس بر روی یک هسته با رفتاری سازگار در سراسر نسخههای لینوکس کافی هستند.
دید بیشتر برنامه
هسته مشترک امکان نظارت بر جزئیات برنامه مانند دسته فایلهای باز را فراهم میکند که استخراج آنها از یک ماشین مجازی کامل دشوار است.
مکانیزم توزیع استاندارد برای ذخیره یک کانتینر در یک رجیستری OCI
بخشی از مشخصات کانتینر نحوه ذخیره و بازیابی یک کانتینر از یک رجیستری را توضیح میدهد – کانتینر بهعنوان یک سری لایههای سیستم فایل ذخیره میشود که بهعنوان یک TAR فشرده (بایگانی نوار) ذخیره میشود، به طوری که لایههای جدید میتوانند فایلها را از لایههای تغییرناپذیر زیرین اضافه و حذف کنند..
برخلاف هر یک از فناوریهای زیر، فناوریهای کانتینری به خودی خود از اجرای برنامهها در یک ماشین منفرد سود میبرند، اما به توزیع یک برنامه در بیش از یک دستگاه نمیپردازند. در زمینه کتاب Building Serverless Applications on Knative، کانتینرها به عنوان یک بستر مشترک عمل میکنند تا به راحتی یک برنامه کاربردی را که میتواند به طور مداوم بر روی یک یا چند رایانه اجرا شود، توزیع میکند.
ارائهدهندگان ابر
ارائهدهندگان ابر شرکتهایی هستند که دسترسی از راه دور به خدمات محاسباتی و ذخیرهسازی را میفروشند. نمونههای محبوب عبارتند از خدمات وب آمازون (AWS)، مایکرؤسافت آزور و پلتفرم ابری گوگل (GCP). خدمات محاسباتی و ذخیرهسازی شامل ماشینهای مجازی، ذخیرهسازی حباب، پایگاههای داده، صفهای پیام و خدمات سفارشی بیشتر است. این شرکتها دسترسی به سرویسها را ساعتی یا حتی به صورت دقیقتر اجاره میدهند، که دسترسی شرکتها به توان محاسباتی را در صورت نیاز بدون نیاز به سرمایهگذاری و برنامهریزی فضای مرکز داده، سختافزار و سرمایهگذاریهای شبکه آسان میکند.
اقتصاد ارائه دهنده ابر
ارائهدهندگان بزرگ ابر بیشتر پول خود را از طریق فروش یا دسترسی مالتی پلکس به سختافزار فیزیکی زیربنایی به دست میآورند – برای مثال، ممکن است سروری را با قیمت ۵۰۰۰ دلار در سال بخرند، اما سپس آن را به ۲۰ اسلات تقسیم کنند که به قیمت ۰. ۰۵ دلار در ساعت میفروشند. برای شرکتی که به دنبال اجاره نیم سرور برای آزمایش برای چند ساعت است، این به معنای دسترسی به ۲۵۰۰ دلار سختافزار با کمتر از ۱ دلار است.
بنابراین، ارائهدهندگان ابری برای بسیاری از انواع مشاغل که تقاضا در آنها روز به روز یا ساعت به ساعت ثابت نیست و دسترسی از طریق اینترنت قابل قبول است، جذاب هستند. اگر ارائهدهنده ابر بتواند سه چهارم دستگاه را بفروشد (۱۵ اسلات × ۰. ۰۵ دلار = ۰. ۷۵ دلار در ساعت درآمد)، میتواند ۰. ۷۵ دلار × ۲۴ × ۳۶۵ = ۶۵۷۰ دلار در سال درآمد داشته باشد – بازگشت سرمایه بدی نیست.
در حالی که برخی از سرویسهای رایانش ابری اساساً «نقطهای از سختافزار را اجاره میکنند»، ارائهدهندگان ابر همچنین برای توسعه سرویسهای مدیریت پیچیدهتر رقابت کردهاند، که یا بر روی ماشینهای مجازی بهازای هر مشتری میزبانی میشوند یا با استفاده از یک رویکرد چند مستأجر که در آن سرورها خود قادر به جداسازی آنها هستند.
کار و منابع مصرف شده توسط مشتریان مختلف در یک فرآیند برنامه واحد. ساختن یک برنامه یا سرویس چند مستأجر سختتر است، اما مزیت آن این است که مدیریت و به اشتراکگذاری منابع سرور بین مشتریان بسیار آسانتر میشود – و کاهش هزینه اجرای سرویس به معنای حاشیههای بهتر برای ارائهدهندگان ابری است.
الگوهای محاسباتی بدون سرور که در کتاب Building Serverless Applications on Knative توضیح داده شده است تا حد زیادی توسط خود ارائهدهندگان ابر یا توسط مشتریانی که راهنمایی و بازخورد در مورد آنچه که خدمات را حتی جذابتر میکند (و در نتیجه ارزش قیمت بالاتری را دارند) ایجاد شدهاند. صرف نظر از اینکه از یک سرویس اختصاصی تک ابری استفاده میکنید یا راهحلی را خود میزبانی میکنید (برای جزئیات بیشتر به بخشهای بعدی و همچنین فصل ۳ کتاب Building Serverless Applications on Knative مراجعه کنید)، ارائهدهندگان ابری میتوانند محیط جذابی را برای تهیه و اجرای برنامههای بدون سرور ارائه دهند.
Kubernetes و Cloud Native
در حالی که ارائهدهندگان ابری کار را با ارائه محاسبات به عنوان نسخههای مجازی سختافزار فیزیکی (به اصطلاح زیرساخت به عنوان سرویس یا IaaS) شروع کردند، به زودی مشخص شد که بسیاری از کارهای ایمنسازی و نگهداری شبکهها و سیستم عاملها تکراری بوده و برای اتوماسیون مناسب است.
یک راهحلایدهآل از کانتینرها بهعنوان روشی تکرارپذیر برای استقرار نرمافزار استفاده میکند، که روی سیستمعاملهای لینوکس مدیریت انبوه با شبکهای «فقط به اندازه کافی» برای اتصال خصوصی کانتینرها بدون قرار گرفتن در معرض اینترنت گسترده اجرا میشود. من الزامات این نوع سیستم را با جزئیات بیشتر در \”فرضهای زیرساخت\” بررسی میکنم.
استارتآپهای مختلفی با موفقیت متوسط تلاش کردند تا راهحلهایی در این فضا ایجاد کنند: Docker Swarm، Apache Mesos و دیگران. در پایان، فناوری معرفی شده توسط گوگل و کمک Red Hat، IBM و دیگران برنده این روز شد – Kubernetes. در حالی که کوبرنتس ممکن است برخی از مزایای فنی نسبت به سیستمهای رقیب داشته باشد، بسیاری از موفقیتهای آن را میتوان به اکوسیستمی که در اطراف پروژه پدید آمد نسبت داد.
Kubernetes نه تنها به یک بنیاد خنثی (Cloud Native Computing Foundation یا CNCF) اهدا شد، بلکه به زودی با سایر پروژههای بنیادی از جمله gRPC و چارچوبهای مشاهدهپذیری، بستهبندی کانتینر، پایگاه داده، پروکسی معکوس و پروژههای مش خدمات به آن ملحق شد. CNCF و اعضای آن علیرغم اینکه یک بنیاد خنثی از فروشنده است، این مجموعه از فناوریها را به طور مؤثر تبلیغ و به بازار عرضه کردند تا توجه و افکار توسعهدهندگان را جلب کنند، و تا سال 2019، تا حد زیادی مشخص بود که ترکیب Kubernetes + Linux پلتفرم کانتینر زیرساخت ترجیحی برای بسیاری از سازمانها خواهد بود.
از آن زمان، Kubernetes تکامل یافته است تا به عنوان یک سیستم همه منظوره برای کنترل سیستمهای زیرساخت با استفاده از یک مدل API استاندارد و قابل توسعه عمل کند. مدل Kubernetes API مبتنی بر تعاریف منابع سفارشی (CRD) و کنترلکنندههای زیرساخت است که وضعیت جهان را مشاهده میکنند و سعی میکنند جهان را مطابق با حالت دلخواه ذخیرهشده در Kubernetes API تنظیم کنند.
این فرآیند به عنوان آشتی شناخته میشود، و زمانی که به درستی اجرا شود، میتواند منجر به سیستمهای انعطافپذیر و خودترمیمی شود که اجرای آنها سادهتر از یک مدل هماهنگ مرکزی است.
فنآوریهای مرتبط با Kubernetes و سایر پروژههای CNCF، فناوریهای بومی ابری نامیده میشوند، چه بر روی ماشینهای مجازی از یک ارائهدهنده ابری پیادهسازی شوند یا روی سختافزار فیزیکی یا مجازی در سازمان خود کاربر.
ویژگیهای کلیدی این فناوریها این است که به صراحت برای اجرا بر روی خوشههایی از رایانهها و شبکههای نیمه قابل اعتماد طراحی شدهاند و در عین حال که در دسترس کاربران باقی میمانند، بهخوبی نقصهای سختافزاری را مدیریت میکنند. در مقابل، بسیاری از فناوریهای بومی پیش از ابر بر اساس گرههای سختافزاری بسیار در دسترس و زائد ساخته شدهاند که تعمیر و نگهداری معمولاً منجر به توقف برنامهریزیشده یا قطعی میشود.
بدون سرور با میزبانی ابری
در حالی که در پنج سال گذشته عجلهای برای تغییر نام بسیاری از فناوریهای ارائهدهنده ابر به عنوان «بدون سرور» رخ داده است، این اصطلاح در ابتدا به مجموعهای از فناوریهای میزبان ابری اشاره داشت که استقرار خدمات را برای توسعهدهندگان ساده میکرد.
به طور خاص، بدون سرور به توسعهدهندگان این امکان را میداد که بر روی برنامههای کاربردی تلفن همراه یا وب تمرکز کنند تا مقدار کمی منطق سمت سرور را بدون نیاز به درک، مدیریت یا استقرار سرورهای برنامه (از این رو نام آن) پیادهسازی کنند. این فناوریها به دو دسته اصلی تقسیم میشوند:
Backend به عنوان یک سرویس (BaaS)
خدمات ذخیرهسازی ساختاریافته با یک API غنی و قابل تنظیم برای مدیریت وضعیت ذخیره شده در یک کلاینت. به طور کلی، این API دارای مکانیزمی برای ذخیرهاشیاء کوچک تا متوسط شیء علامتگذاری جاوا اسکریپت (JSON) در یک فروشگاه ارزش کلیدی با قابلیت ارسال اعلان فشار دستگاه هنگام تغییر یک شی در سرور بود.
APIها همچنین از تعریف اعتبار سنجی شی سمت سرور، احراز هویت خودکار و مدیریت کاربر، و قوانین امنیتی آگاه از سرویس گیرنده موبایل پشتیبانی میکنند. پرطرفدارترین نمونهها Parse (در سال ۲۰۱۳ توسط فیس بوک، اکنون متا خریداری شد و در سال ۲۰۱۷ منبع باز شد) و Firebase (در سال ۲۰۱۴ توسط گوگل خریداری شد) بودند.
BaaS در حالی که برای شروع یک پروژه با یک تیم کوچک مفید بود، در نهایت با چند مشکل مواجه شد که باعث شد محبوبیت آن از بین برود:
اکثر برنامهها در نهایت از عملکرد ثابت پیشی گرفتند. در حالی که پذیرش BaaS ممکن است بهره وری اولیه را افزایش دهد، تقریباً مطمئناً مهاجرت ذخیرهسازی آینده و بازنویسی در صورت محبوب شدن برنامه را تضمین میکند.
در مقایسه با سایر گزینههای ذخیرهسازی، هم گران بود و هم مقیاسبندی محدودی داشت. در حالی که توسعهدهندگان برنامهها نیازی به مدیریت سرورها نداشتند، بسیاری از معماریهای پیادهسازی برای اجتناب از مدلهای قفل شی پیچیده به یک سرور frontend نیاز داشتند.
عملکرد به عنوان یک سرویس (FaaS)
در این مدل، توسعهدهندگان برنامهها توابع جداگانهای نوشتند که در صورت برآورده شدن شرایط خاص، فراخوانی میشوند. در برخی موارد، این با BaaS ترکیب شد تا برخی از مشکلات عملکرد ثابت را حل کند، اما همچنین میتوان آن را با سرویسهای ذخیرهسازی ارائهدهنده ابری مقیاسپذیر برای دستیابی به معماریهای مقیاسپذیرتر ترکیب کرد. در مدل FaaS، هر فراخوانی تابع مستقل است و ممکن است به صورت موازی، حتی در کامپیوترهای مختلف، رخ دهد.
هماهنگی بین فراخوانی تابع باید به طور صریح با استفاده از تراکنشها یا قفلها انجام شود، نه اینکه به طور ضمنی توسط API ذخیرهسازی مانند BaaS مدیریت شود. اولین پیادهسازی گسترده FaaS AWS Lambda بود که در سال ۲۰۱۴ راهاندازی شد. در عرض چند سال، اکثر ارائهدهندگان ابری خدمات رقیب مشابهی را ارائه کردند، البته بدون هیچ گونه API استاندارد.
برخلاف IaaS، ارائههای FaaS ارائهدهنده ابر معمولاً در هر فراخوانی یا در هر ثانیه از اجرای عملکرد، با حداکثر مدت زمان ۵ تا ۱۵ دقیقه در هر فراخوان صورتحساب میشوند. صورتحساب به ازای هر فراخوان میتواند منجر به هزینههای بسیار پایین برای عملکردهای کم استفاده شود، و همچنین صورتحساب مطلوب برای حجمهای کاری سنگین که هزاران درخواست دریافت میکنند و سپس برای چند دقیقه یا ساعت بیکار میمانند.
برای فعال کردن این مدل صورتحساب، ارائهدهندگان ابری پلتفرمهای چند مستأجری را اجرا میکنند که عملکردهای هر کاربر را از یکدیگر جدا میکنند، علیرغم اینکه روی سختافزار فیزیکی یکسانی در عرض چند ثانیه از یکدیگر اجرا میشوند.
تا حدود سال ۲۰۱۹، \”بدون سرور\” بیشتر با FaaS مرتبط شد، زیرا BaaS از بین رفته بود. از آن نقطه، نام بدون سرور شروع به استفاده برای خدمات غیر محاسباتی کرد، که به خوبی با مدل صورتحساب FaaS کار میکرد: هزینه فقط برای تماسهای دسترسی و فضای ذخیرهسازی مورد استفاده، نه برای واحدهای سرور طولانیمدت.
ما تفاوتهای بین محاسبات سنتی سروردار و بدون سرور را در فصل ۱ کتاب Building Serverless Applications on Knative مورد بحث قرار خواهیم داد، اما این تعریف جدید به مفهوم بدون سرور اجازه میدهد تا به سیستمهای ذخیرهسازی و سرویسهای تخصصی مانند رمزگذاری ویدیو یا تشخیص تصویر هوش مصنوعی گسترش یابد.
در حالی که تعاریف «ارائهدهنده ابر» یا «نرمافزار بومی ابری» ذکر شده در طول زمان تا حدودی روان بوده است، نام بدون سرور بهویژه روان بوده است – یک علاقهمند به سرور بدون سرور از سال ۲۰۱۴ با اکثر خدمات ارائه شده تحت این نام هشت سال کاملاً گیج میشود. بعد.
یکی از آخرین نکات ابهامزدایی: شبکههای مخابراتی ۵G اصطلاح گیجکننده «عملکرد شبکه بهعنوان یک سرویس» را معرفی کرده است، که اینایده این است که رفتار مسیریابی شبکه طولانیمدت مانند فایروالها میتواند بهعنوان یک سرویس در یک پلتفرم مجازی اجرا شود که با آن ارتباطی ندارد. هر ماشین فیزیکی خاصی در این مورد، اصطلاح \”عملکرد شبکه\” به جای معماری توزیع شده بدون سرور، به معماری متفاوتی با سرورهای با عمر طولانی اما سیار دلالت دارد.
کتاب Building Serverless Applications on Knative چگونه سازماندهی شده است؟
کتاب Building Serverless Applications on Knative به چهار بخش اصلی تقسیم شده است. ۲ من تمایل دارم با ایجاد یک مدل ذهنی از آنچه در حال وقوع است، یاد بگیرم، سپس چیزهایی را امتحان کنم تا ببینم مدل ذهنی من در کجا درست نیست، و در نهایت پس از استفاده طولانی، تخصص عمیقی را ایجاد کنم. قطعات با این مدل مطابقت دارند – آنهایی که در جدول P-۱ هستند.
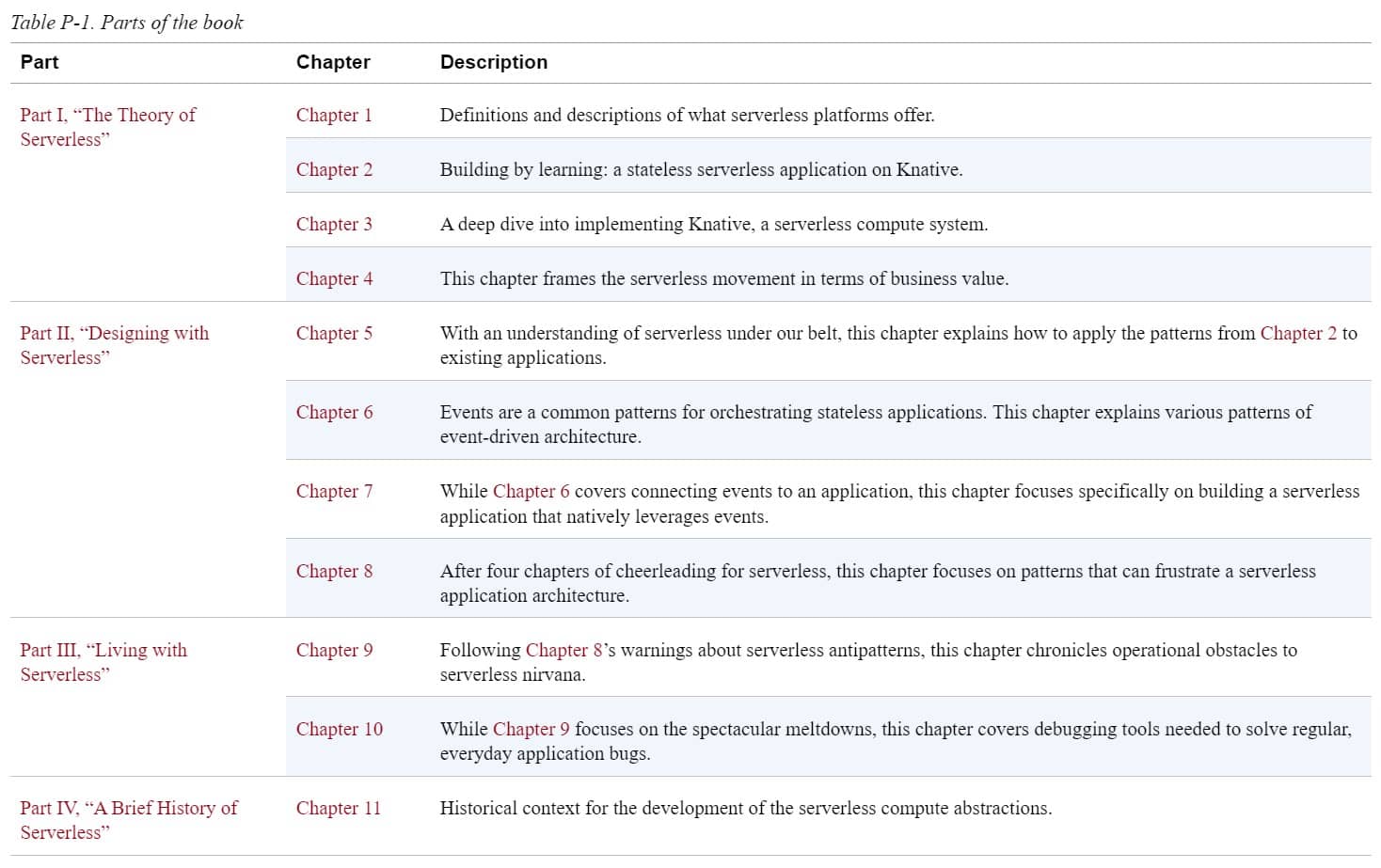
سرفصلهای کتاب Building Serverless Applications on Knative:
- Preface
- I. The Theory of Serverless
- 1. What Is Serverless, Anyway?
- 2. Designing from Scratch
- 3. Under the Hood: Knative
- 4. Forces Behind Serverless
- II. Designing with Serverless
- 5. Extending the Monolith
- 6. More on Integration: Event-Driven Architecture
- 7. Developing a Robust Inner Monologue
- 8. Too Much of a Good Thing Is Not a Good Thing
- III. Living with Serverless
- 9. Failing at the Speed of Light
- 10. Cracking the Case: Whodunnit
- IV. A Brief History of Serverless
- 11. A Brief History of Serverless
- Index
- About the Author
جهت دانلود کتاب Building Serverless Applications on Knative میتوانید پس از پرداخت، دریافت کنید.
دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.