

{kind=link}
{kind=link}
{kind=link}
کتاب Data Science: A First Introduction with Python (علم داده: اولین مقدمه با پایتون) بر استفاده از زبان برنامه نویسی پایتون در نوت بوک های Jupyter برای انجام دستکاری و پاکسازی داده ها، ایجاد تجسم های موثر و استخراج بینش از داده ها با استفاده از طبقه بندی، رگرسیون، خوشه بندی و استنتاج تمرکز دارد.
در ادامه مقدمهای از کتاب Data Science: A First Introduction with Python را از زبان نویسنده شرح خواهیم داد.
مقدمهای بر کتاب Data Science: A First Introduction with Python:
این کتاب آموزشی قصد دارد یک مقدمه قابل دسترسی به دنیای علم داده باشد. در این کتاب، علم داده را به عنوان فرآیند تولید بینش از دادهها از طریق فرآیندهای قابل تکرار و قابل حسابرسی تعریف میکنیم.
اگر برخی از دادهها را تجزیه و تحلیل کنید و تحلیل خود را به یک دوست یا همکار ارائه دهید، آنها باید بتوانند تحلیل را از ابتدا تا انتها مجدداً اجرا کنند و همان نتیجه را بگیرند که شما کردهاید (قابل تکرار بودن). آنها همچنین باید بتوانند تمام مراحل تحلیل و تاریخچه چگونگی توسعه تحلیل را ببینند و درک کنند (قابل حسابرسی بودن). ایجاد تحلیلهای قابل تکرار و قابل حسابرسی به شما و دیگران اجازه میدهد تا به راحتی کار خود را دوباره بررسی و اعتبارسنجی کنید.
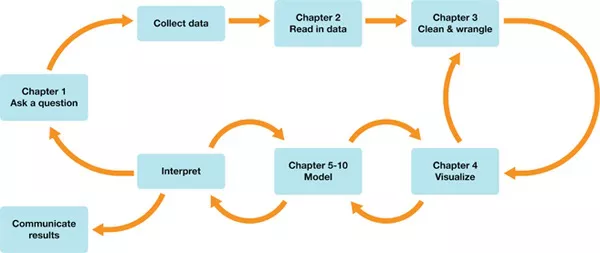
در سطح بالا، در کتاب Data Science: A First Introduction with Python، یاد خواهید گرفت که چگونه مشکلات رایج در علم داده را شناسایی کنید و این مشکلات را با گردش کارهای قابل تکرار و قابل حسابرسی حل کنید. شکل 1 آنچه را که در هر فصل از این کتاب یاد خواهید گرفت خلاصه میکند. در طول کتاب، یاد خواهید گرفت که چگونه از زبان برنامهنویسی پایتون برای انجام تمام وظایف مرتبط با تحلیل دادهها استفاده کنید.
شما چهار فصل اول را صرف یادگیری نحوه استفاده از پایتون برای بارگیری، تمیز کردن، دستکاری (یعنی بازسازی دادهها در یک قالب قابل استفاده) و تجسم دادهها در حین پاسخ به سوالات تحلیل دادههای توصیفی و اکتشافی خواهید کرد. در شش فصل بعدی، یاد خواهید گرفت که چگونه با روشهای رایج در علم داده، از جمله طبقهبندی، رگرسیون، خوشهبندی و برآورد، به سوالات تحلیل دادههای پیشبینیکننده، اکتشافی و استنتاجی پاسخ دهید.
در فصلهای پایانی کتاب Data Science: A First Introduction with Python یاد خواهید گرفت که چگونه کد پایتون، متن قالببندی شده و تصاویر را در یک سند منسجم واحد با Jupyter ترکیب کنید، از کنترل نسخه برای همکاری استفاده کنید و نرمافزار مورد نیاز برای علم داده را روی رایانه خود نصب و پیکربندی کنید.
اگر این کتاب را به عنوان بخشی از یک دوره که در آن شرکت میکنید میخوانید، ممکن است مدرس تمام این ابزارها را قبلاً برای شما تنظیم کرده باشد؛ در این صورت، میتوانید با خواندن فصلها به ترتیب به کتاب ادامه دهید. اما اگر به صورت مستقل میخوانید، ممکن است بخواهید قبل از ادامه، به این سه فصل آخر بپرید تا مطمئن شوید رایانه شما به گونهای تنظیم شده است که میتوانید کد نمونهای را که در سراسر کتاب گنجاندهایم امتحان کنید.
هر فصل از کتاب Data Science: A First Introduction with Python دارای یک برگه کار همراه است که تمریناتی را برای کمک به شما در تمرین مفاهیمی که یاد خواهید گرفت ارائه میدهد. ما اکیدا توصیه میکنیم که پس از اتمام خواندن هر فصل و قبل از رفتن به فصل بعدی، روی برگه کار کار کنید.
سرفصلهای کتاب Data Science: A First Introduction with Python:
- Cover Page
- Half-Title Page
- Series Page
- Title Page
- Copyright Page
- Contents
- Preface
- Foreword
- Acknowledgments
- About the authors
- 1 Python and Pandas
- 2 Reading in data locally and from the web
- 3 Cleaning and wrangling data
- 4 Effective data visualization
- 5 Classification I: training & predicting
- 6 Classification II: evaluation & tuning
- 7 Regression I: Knearest neighbors
- 8 Regression II: linear regression
- 9 Clustering
- 10 Statistical inference
- 11 Combining code and text with Jupyter
- 12 Collaboration with version control
- 13 Setting up your computer
- Bibliography
- Index
جهت دانلود کتاب Data Science: A First Introduction with Python میتوانید پس از پرداخت، دریافت کنید.
دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.