

{kind=link}
{kind=link}
{kind=link}
{kind=link}
کتاب Machine Learning for Social and Behavioral Research (یادگیری ماشین برای تحقیقات اجتماعی و رفتاری) مفاهیم کاربردی و مربوط به یادگیری ماشین در زمینهی اجتماعی و رفتاری جامعه مطرح میکند.
در ادامه مقدمهای از کتاب Machine Learning for Social and Behavioral Research را از زبان نویسنده شرح خواهیم داد.
مقدمهای بر کتاب Machine Learning for Social and Behavioral Research:
در طول 20 سال گذشته، تغییرات باورنکردنی در اندازه، ساختار و انواع دادههای جمعآوری شده در علوم اجتماعی و رفتاری رخ داده است. بنابراین، محققان اجتماعی و رفتاری به طور فزایندهای این سوال را مطرح میکنند که «با همه این دادهها چه کنم؟» هدف این کتاب کمک به پاسخ به این سوال است.
با پیشرفت در جمعآوری دادهها، گسترش متناظری در درک پیچیدگی زیربنای روابط بین متغیرها وجود داشته است. اثرات و تعاملات غیرخطی در حال حاضر به طور منظم به عنوان فرضیه مطرح میشوند، به کمک حجم نمونه بزرگتر که قدرت آماری کافی را فراهم میکند. علاوه بر این، پیشبینی یک نتیجه تنها با چند متغیر مورد علاقه، در حالی که فقط روابط خطی را ارزیابی میکند، اکنون بهشدت محدودکننده شناخته میشود. در حالی که این رویکرد در گذشته رایج بود، به دلیل حجم دادههای کوچکتر و محدودیتهای نرمافزار آماری، جمعآوری دادهها به کمک رایانه و نرمافزار جدید به غلبه بر چنین چالشهایی کمک کردهاند.
در گذشته، بهویژه در تحقیقات دانشگاهی، انواع خاصی از دادهها تنها با انواع خاصی از مدلهای آماری مانند تحلیل واریانس (ANOVA) و رگرسیون خطی، که با انگیزه نظری زیربنای مطالعه همسو بودند، تجزیه و تحلیل میشد. با این حال، ظهور روشهای جدید جمعآوری دادهها منجر به انواع دادههای جدید (به عنوان مثال، متن)، استخراجشده از منابع مختلف (مانند تصویربرداری مغز، شبکههای اجتماعی)، و همچنین مجموعههای بزرگتری از دادههای نظرسنجی سنتی شده است. در نتیجه، انعطاف پذیری باورنکردنی در انتخاب الگوریتمها وجود دارد.
این امر کاربردهای آماری مدرن را پیچیده میکند، زیرا محققان و متخصصان باید با یک بعد اضافی، به طور خاص، “کدام الگوریتم یا الگوریتمها را اعمال کنم؟” و “این الگوریتم چگونه با انگیزههای نظری مطالعه من همسو میشود؟”
نظر ما این است که در تحقیقات اجتماعی و رفتاری، برای پاسخ به این سوال که «با همه این دادهها چه کنم؟» نیاز است که آخرین پیشرفتهای الگوریتمها را بدانیم و در مورد تأثیر متقابل الگوریتمهای آماری، دادهها، عمیقاً فکر کنیم. و نظریه. یک تمایز مهم بین این کتاب و بسیاری از کتابهای دیگر در زمینه یادگیری ماشین، تمرکز ما بر نظریه است.
شکل 1. برای پرداختن به تعامل، پیچیدگی تجزیه و تحلیل دادههای مدرن مستلزم انتقال از تمرکز اصلی بر تعامل دادهها و تئوری، به درک نحوه ادغام دادهها، نظریهها و الگوریتمها در عمل است.
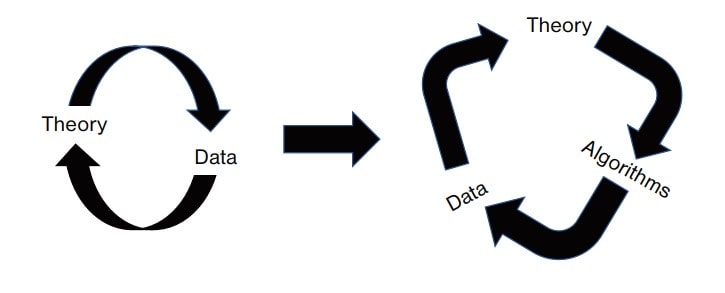
در مورد یادگیری ماشین، دادهها و تئوری (به شکل 1 مراجعه کنید)، ما با جزئیات دیدگاه خود در فصل 2 کتاب Machine Learning for Social and Behavioral Research شروع میکنیم تا به سؤالی که اغلب هنگام آموزش کلاسها یا کارگاههای آموزشی در مورد یادگیری ماشین دریافت میکنیم، بپردازیم، یعنی: “آیا میتوان تجزیه و تحلیلهای یادگیری ماشین را در من گنجاند.
تحقیقات تاییدی سنتی؟ سوال بعدی اغلب این است: “با توجه به ماهیت اکتشافی یادگیری ماشینی، چگونه میتوانیم مطمئن باشیم که نتایج ما قابل اعتماد هستند؟” ما به این سوال به طور خاص در فصل 3 کتاب Machine Learning for Social and Behavioral Research با ارائه جزئیات در مورد تعدادی از استراتژیهای اعتبار سنجی متقابل که به جلوگیری از برازش بیش از حد کمک میکند، پاسخ میدهیم.
یک نگاه به فهرست مطالب هر یک از کتابهای اخیراً منتشر شده در مورد یادگیری ماشین، داده کاوی، یادگیری آماری، علم داده یا هوش مصنوعی مجموعهای گیجکننده از الگوریتمها را نشان میدهد که در کتابهای درسی آمار سنتی جزئیاتی ندارند. این کتاب از چند جهت متفاوت است.
اولین مورد، تمرکز فوق الذکر ما بر نظریه است. در حالی که فصل 1 جهتگیری را برای سازمان کتاب ارائه میکند، ماده اولیه کتاب ما با تمرکز بر نظریه (فصل 2) آغاز میشود – یعنی اینکه چگونه یادگیری ماشین در تحقیقاتی که به طور سنتی از دیدگاه فرضیهمحور انجام میشود، قرار میگیرد.
این با فصلی (فصل 3) در مورد اصول دنبال میشود، بهویژه اینکه چگونه پزشکان میتوانند از الگوریتمهای یادگیری ماشین برای تولید نتایج قابل اعتماد استفاده کنند. این فصلها زمینه را برای بحث ما در مورد الگوریتمهای نتایج تک متغیره فراهم میکند (فصل 4-6). با این حال، بر خلاف کتابهای دیگر، ما تا حد زیادی بر روشهای منظم و درختی تمرکز میکنیم.
این بهتر به ما اجازه میدهد تا در مورد ادغام این الگوریتمها با مدلهای پیچیده که معمولاً در تحقیقات اجتماعی و رفتاری استفاده میشوند، یعنی مدلهای متغیر پنهان، بحث کنیم. این ما را قادر میسازد تا جزئیات بیشتری در مورد خطای اندازهگیری، یک جزء بسیار مهم از دادههای نظرسنجی، تجزیه و تحلیل دادههای طولی، و ارزیابی ناهمگونی از طریق شناسایی زیرگروهها ارائه دهیم.
اندازهگیری تمرکز فصلهای 7 و 8 کتاب Machine Learning for Social and Behavioral Research است و پس از آن بحثی در مورد مدل سازی دادههای طولی (فصل 9) و ارزیابی ناهمگونی (فصل 10) ارائه میشود. در نهایت، ما دو فصل آخر را بر روی انواع دادههای جایگزین متمرکز میکنیم، با مقدمهای بر تجزیه و تحلیل متن (فصل 11)، که در آن پردازش دادههای متنی و اجرای الگوریتمهای رایج کاربردی، و دادههای شبکه اجتماعی (فصل 12) را با تاکید شرح میدهیم. در مورد مدل سازی شبکه فصلهای 1 تا 6، 9 و 11 کتاب Machine Learning for Social and Behavioral Research به عنوان منبع اصلی برای دورههای پیشرفته کارشناسی و کارشناسی ارشد استفاده شده است.
علاوه بر این، کتاب Machine Learning for Social and Behavioral Research میتواند به عنوان یک مطالعه تکمیلی برای دروس رگرسیون، چند متغیره، دادههای طولی، و مدل سازی معادلات ساختاری و غیره استفاده شود.
در حالی که فصلهای 4 تا 6 کتاب Machine Learning for Social and Behavioral Research همپوشانی قابلتوجهی با محتوای یافت شده در سایر کتابهای مرتبط با یادگیری نظارت شده دارند، فصل 7 و فصلهای بعدی کتاب Machine Learning for Social and Behavioral Research شرح مفصلتر/پیشرفتهتری از روشهای یادگیری ماشین ارائه میدهند.
فصلها وسعتی در پوشش روششناسی و الگوریتمها با تمرکز عمیق بر موضوعات اساسی دارند که در ابتدای هر فصل در بخش «اصطلاحات کلیدی» به تفصیل آمده است تا خوانندگان را برای مفاهیم اساسی هر فصل آماده کند.
علاوه بر این، فصلهای 3 تا 12 کتاب Machine Learning for Social and Behavioral Research را با بخش «زمان و منابع محاسباتی» به پایان میبریم که نحوه اجرای هر روش را مورد بحث قرار میدهد و بستههای کلیدی R را نشان میدهد که میتوان استفاده کرد. هر کاربرد یادگیری ماشینی که در این کتاب شرح داده شده است در محیط آماری R برنامه ریزی شده است. در حالی که کتاب جزئیات کد R را ارائه نمیدهد، کد برای همه تجزیه و تحلیلها در وب سایت کتاب ارائه شده است. خوانندگان میتوانند از این کد برای بازتولید هر نمونه در کتاب استفاده کنند.
سرفصلهای کتاب Machine Learning for Social and Behavioral Research:
- Cover
- Half Title Page
- Series Page
- Title Page
- Copyright
- Series Editor’s Note
- Preface
- Contents
- Part I. Fundamental Concepts
- 1. Introduction
- 2. The Principles of Machine Learning Research
- 3. The Practices of Machine Learning
- Part II. Algorithms for Univariate Outcomes
- 4. Regularized Regression
- 5. Decision Trees
- 6. Ensembles
- Part III. Algorithms for Multivariate Outcomes
- 7. Machine Learning and Measurement
- 8. Machine Learning and Structural Equation Modeling
- 9. Machine Learning with Mixed-Effects Models
- 10. Searching for Groups
- Part IV. Alternative Data Types
- 11. Introduction to Text Mining
- 12. Introduction to Social Network Analysis
- References
- Author Index
- Subject Index
- About the Authors
جهت دانلود کتاب Machine Learning for Social and Behavioral Research میتوانید پس از پرداخت، دریافت کنید.
دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.