

کتاب Practical Full Stack Machine Learning
اثر Alok Kumar
نوع محتوای کتاب
مبتنی بر پروژه
هدف یادگیری
ارتقای شغلی
نوع مسیر
مرجع / کتابچه راهنما
بر اساس تکنولوژی
دوآپس
مورد استفاده
دوآپس
بر اساس سطح علمی
متوسط
info نکات مهم قبل از خرید:
- نسخه کتاب فعلی به زبان لاتین میباشد.
- کتاب به صورت محصول میباشد و پس از خرید بلافاصله در دسترس شما قرار میگیرد.
- قبل از خرید، قسمت توضیحات تکمیلی مربوط به هر کتاب را مطالعه کنید.
- در صورت هرگونه سؤال با ایمیل و یا شماره پشتیبانی سایت در تماس باشید.
- درگاه پرداخت رمزارز نیز برای هموطنان خارج از کشور فعال است.
درباره این کتاب
کتاب Practical Full Stack Machine Learning یک منبع کاملاً حرفهای و عملی برای آموزش یادگیری ماشین میباشد. این کتاب از آخرین فناوریها و متدهای روز دنیا برای آموزش یادگیری ماشین به شما بهره برده است. کتاب Practical Full Stack Machine Learning در 7 فصل و حدود 750 صفحه به آموزش پایه تا پیشرفتهی علم یادگیری ماشین پرداخته و شما را با تکنیکهای آن آشنا میکند. در ادامه مقدمهای از کتاب…

کتابهای پیشنهادی این تخصص:
کتابهای پیشنهادی این تخصص:
نظرات کاربران
تجربیات خود را از خواندن این کتاب با دیگران به اشتراک بگذارید.
ثبت نظر جدید
هنوز دیدگاهی ثبت نشده است.
کتاب Practical Full Stack Machine Learning یک منبع کاملاً حرفهای و عملی برای آموزش یادگیری ماشین میباشد. این کتاب از آخرین فناوریها و متدهای روز دنیا برای آموزش یادگیری ماشین به شما بهره برده است. کتاب Practical Full Stack Machine Learning در 7 فصل و حدود 750 صفحه به آموزش پایه تا پیشرفتهی علم یادگیری ماشین پرداخته و شما را با تکنیکهای آن آشنا میکند.
در ادامه مقدمهای از کتاب Practical Full Stack Machine Learning را از زبان نویسنده شرح خواهیم داد.
مقدمهای بر کتاب Practical Full Stack Machine Learning:
یک پروژه موفق علم داده فقط ساخت مدلهای قدرتمند نیست، بلکه اجرای کارآمد کل چرخه عمر پروژه است. متأسفانه، علم داده مانند ART و دانشمند داده به عنوان ARTIST ساخته شده است که از ترفندهای سخت برای حدس زدن و غیرقابل توضیح استفاده میکند.
اگر تصمیمگیری در مورد مقداردهی اولیه صحیح پارامترهای هایپر یا اجرای مجدد کد آموزشی مدل شخص دیگری برایتان دشوار است، در این صورت درد و ناامیدی جامعه دانشمندان داده را به اشتراک میگذارید. تجربه ممکن است ترفندهای کمی را به شما بیاموزد، اما محدودیتهایی وجود دارد که چقدر میتوانیم آنها را در زمان نیاز به خاطر بسپاریم و بهدقت به یاد آوریم.
همچنین، در طرح بزرگ چیزها، آموزش ML بخشی از یک ماشین داده بزرگتر است. این بدان معناست که ورودی ها و خروجی ها همیشه به سایر بخشهای سیستم وابسته خواهند بود. مایلیم در اینجا مکث کنید و به این سوال فکر کنید – چگونه مدل تولید شده خود را که از برآوردن الزامات یا یک قدم قبل از آن ناتوان است – برگردانید – چگونه متوجه میشوید که خراب است یا دقت از حد مجاز پایین آمده است؟ باز هم، چند ترفند از این دست را در کل خط لوله میتوانید یاد بگیرید، به خاطر بسپارید و به خاطر بیاورید؟
هدف کتاب Practical Full Stack Machine Learning این است که شما را با مجموعه ای از ابزارها و مفاهیم متن باز قدرتمند و مورد نیاز برای ایجاد یک خط لوله موثر علم داده آشنا کند تا نیازی به یادآوری ترفندها نباشد، بلکه فقط ابزارهای مناسب را به خاطر بسپارید، که حدس میزنیم و طبق تجربه من، انجام این کار بسیار ساده تر است. برای اطمینان از اینکه هیجان را با من به اشتراک میگذارید –
این مثال را در نظر بگیرید.
شما میخواهید سهام بخرید و از این رو تصمیم گرفتید از مشاوران مشاوره بگیرید. به عنوان یک سرمایه گذار با تجربه، میخواهید از مشاوره دیگران نیز استفاده کنید. در اینجا این است که چگونه ممکن است به نظر برسد.
درصد، میزان دقت است.
- مشاور مالی – 75٪
- معامله گر بورس – 70%
- تیم تحقیقات بازار – 75٪
- کارشناس رسانه های اجتماعی – 60٪
همانطور که به وضوح مشاهده میشود، همه پیشبینیهای متخصصان زیر 75٪ است، اما اگر همه پیشبینیهای آنها را ترکیب کنید، تصویر کاملا متفاوتی خواهید داشت.
میزان دقت = 1- (25%* 30% * 25% * 40%) = 99.25%
این قدرت «همآمیزی» است و در دنیای یادگیری ماشینی، یادگیری گروهی اساساً ترکیبی از چندین تکنیک یادگیری ماشینی است که با هم انجام میشوند.
اکنون، برای آزمایش تکنیکهای مختلف گروهبندی، میتوانید آن را از ابتدا بنویسید، یا میتوانید از کتابخانه ML-Ensemble استفاده کنید. ML-Ensemble یک API سطح بالای Scikit-learn را با یک چارچوب نمودار محاسباتی سطح پایین ترکیب میکند تا شبکههای مجموعهای کارآمد و حداکثر موازیشده را در کمترین خط کد ممکن بسازد.
ما امیدواریم که این ایده و هدف کتاب Practical Full Stack Machine Learning را به سمت اصلی هدایت کند. از آنجایی که کتاب در مورد ایجاد خطوط لوله و سیستمهای مؤثر است، ما کتابها را حول مراحل مشترک پروژه علم داده سازماندهی کردهایم.
مراحل به این صورت است:
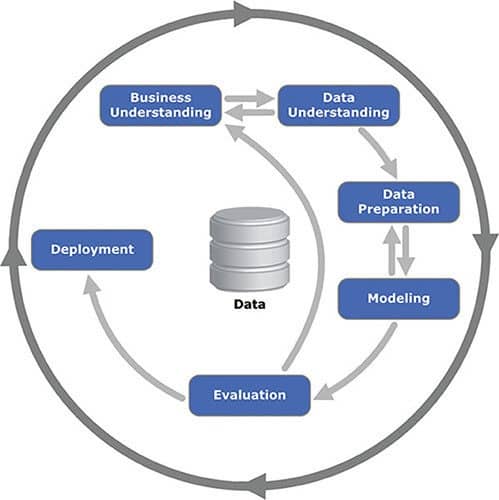
شکل 0.1: مراحل متداول CRISM DM
من مطمئن هستم که قبلاً تصویر یا نموداری مانند این را دیده بودید. مراحل آنقدر رایج است که هیچ سر به سر نمیبرد. آنقدر منطقی به نظر میرسد که به سختی میتوان باور کرد که تلاش قابل توجهی برای ایجاد این فرآیند شهودی صرف شده است. جالب اینجاست که این قبل از اینکه علم داده به جذابترین شغل تبدیل شود ایجاد شد.
…
C RISP DM یا فرآیند استاندارد Cross Industry برای دادهکاوی یک روش فرآیند برای کاربردهای داده کاوی است. در حالی که روشهای دیگری نیز وجود دارد، CRISP DM یکی از انتخابهای محبوب است.
شما میتوانید انواعی از فرآیندها را بیابید که با ابزارهای دادهکاوی بسیاری سازگار شده اند بدون اینکه هیچ گونه نسبتی به آن بدهید. هدف CRISP DM ارائه یک فرآیند تکرارپذیر مستقل در صنعت برای کار دادهکاوی است. اخیراً CRISP DM به آرامی شروع به کنار زدن کرده است، اما اصول اساسی هنوز قوی و مفید هستند.
فصلهای کتاب Practical Full Stack Machine Learning بهطور آزادانه پیرامون مراحل مختلف CRISP DM سازماندهی شدهاند. هدف، ارائه چارچوبی برای گروهبندی ابزارها و کتابخانههای مختلف است. ذهن ما توانایی شگفتانگیزی دارد که به راحتی چیزهایی را که گروهبندی/متصل شدهاند به یاد بیاورد.
در اینجا نحوه سازماندهی فصل های کتاب Practical Full Stack Machine Learning آمده است.
فصل 1: سازماندهی پروژه علم داده خود پروژههای علم داده ماهیت آزمایشی دارند و نحوه سازماندهی پروژه شما تأثیر زیادی بر سهولت و سرعت آزمایشات شما دارد. یک مدل یادگیری ماشین کد به اضافه داده است و از این رو هر دو باید به درستی سازماندهی شوند. شروع کار فقط در مورد سازماندهی پروژه شما نیست، بلکه تصمیمگیری در مورد محیط، چارچوب، خط مبنا، معیارهای هدف و در این فصل از کتاب Practical Full Stack Machine Learning، مفاهیم، ابزارها و ایدههایی را بررسی خواهیم کرد که به ارائه بهترین راه کمک میکند.
فصل 2: آمادهسازی دادههای خود برای پروژه علم داده شرح: جمعآوری و آمادهسازی دادهها پایه و اساس مدلهای یادگیری ماشینی/یادگیری عمیق است. تلاش قابل توجهی در این مرحله صرف میشود. تمرکز این فصل بر یادگیری بهترین شیوهها، ابزارهای تجزیه و تحلیل دادهها و پیش پردازش برای پروژههای یادگیری ماشین خواهد بود.

فصل 3: ساختن معماری خود برای پروژههای علم داده خود ساختن معماری شما استفاده از آخرین الگوریتم محبوب و ویروسی برای ساخت مدل نیست، بلکه آموزش مدلی است که انتظارات و چالش های دنیای واقعی را برآورده میکند. تمرکز این فصل از کتاب Practical Full Stack Machine Learning، بر یادگیری بهترین روشها در انتخاب الگوریتم، راهاندازی/تنظیم فراپارامترها و تکنیکهای اشکالزدایی برای بهبود عملکرد مدل خواهد بود.
فصل 4: زمانبند خداحافظی، جریان هوا خوش آمدید جریان هوای آپاچی یک پروژه منبع باز است که به صورت برنامهنویسی، برنامهریزی و نظارت بر گردشهای کاری را انجام میدهد. مزیت کلیدی خطوط لوله یادگیری ماشین، اتوماسیونی است که برای مراحل مختلف ارائه میدهد. هر مجموعه داده آموزشی جدید باید مراحل مشخص شده در فرآیند CRISP DM را طی کند. اکثر تیم یا به صورت دستی این کار را انجام میدهند یا با چسب نواری مراحل آن را بسیار شکننده میکنند. اگر مدل شما کاربر دارد، به خط لوله نیاز دارید. اگر هنوز متقاعد نشدهاید، فصل 5 این کار را انجام خواهد داد. هدف این فصل از کتاب Practical Full Stack Machine Learning، معرفی ملایم جریان هوا است.

فصل 5: مدیریت خط لوله ML با MLflow اکثریت ما از اجرای کد به اضافه مدل شخص دیگری ناامید شدهایم. وابستگیهای کتابخانهها، پیکربندیهای پنهان و مراحل راهاندازی غیرمستند، رفتار با مدل شخص دیگری مانند جعبه سیاه را بسیار دشوار میکند.
MLflow یک پروژه منبع باز است که به شما کمک میکند مدلها را با هر کتابخانهای آموزش دهید، از آنها استفاده مجدد کنید، و آنها را در مراحل تکرارپذیر بستهبندی کنید که سایر دانشمندان داده میتوانند به عنوان یک “جعبه سیاه” استفاده کنند، بدون اینکه حتی نیازی به دانستن اینکه از کدام کتابخانه استفاده میکنید. هدف این فصل از کتاب Practical Full Stack Machine Learning، این است که شما را با MLflow و نحوه استفاده از آن در موقعیتهای خود آشنا کند.
فصل 6: انبارهای ویژگی برای ML Feature store را میتوان به عنوان انباری از ویژگیها تصور کرد. این طاق مرکزی برای ذخیره ویژگی های مستند و کنترل شده با دسترسی است. ابنبار ویژگی یک مفهوم نوظهور با هدف از بین بردن چالشها در انتقال مدلهای ML به تولید است. تمرکز این فصل از کتاب Practical Full Stack Machine Learning، یادگیری در مورد انبارهای ویژگی از طریق یک انبار ویژگی منبع باز به نام feast است.

فصل 7: ارائه ML به عنوان API تمرکز این فصل از کتاب Practical Full Stack Machine Learning، بر این است که چگونه میتوانیم مدل ML را به عنوان یک API استقرار دهیم. ما از fastAPI استفاده خواهیم کرد که یک چارچوب وب مدرن و با کارایی بالا پایتون است که برای ساخت API های RESTful عالی است.
fastAPI میتواند درخواستهای همزمان و ناهمزمان را مدیریت کند و دارای پشتیبانی داخلی برای اعتبارسنجی دادهها، سریالسازی JSON، احراز هویت و مجوز است. به عنوان یک جایزه، شما همچنین در مورد این که فصلها مستقل هستند و میتوانند در هر دنبالهای خوانده شوند، یاد خواهید گرفت. این بسیار مفید است زیرا ممکن است شما به چند فصل علاقهمند باشید یا ممکن است فوراً دانش برخی از فصلها مورد نیاز باشد.
بیشتر بخوانید: کتاب Building Data Science Applications with FastAPI
این ممکن است کلیشه ای به نظر برسد، اما درست است – بهترین راه برای یادگیری و به خاطر سپردن تمرین و تکرار است. سعی کنید یادداشتهایی برای هر فصل تهیه کنید و مرتباً آنها را مرور کنید. تکرار به شما کمک میکند اکنون در مورد فصلی که میخواهید شروع کنید و ادامه دهید تصمیم بگیرید.
سرفصلهای کتاب Practical Full Stack Machine Learning:
- Chapter 1:Organizing your data science project
- Chapter 2:Preparing your data for Data science project
- Chapter 3:Building your architecture for your data science projects
- Chapter 4: Bye-Bye Scheduler, welcome airflow
- Chapter 5:Managing ML pipeline with MLflow
- Chapter 6:Feature stores for ML
- Chapter 7:Serving ML as API
فایل کتاب Practical Full Stack Machine Learning را میتوانید پس از پرداخت، دریافت کنید.